KittenTTS es un modelo ligero de texto a voz ,que puede funcionar prácticamente en cualquier lugar, incluso desde un navegador web, pero únicamente genera audio en inglés.
Tabla de contenidos
🖥️ Requisitos:
🐍 Python 3.12
Descargar versión portable mínima Winpython: https://github.com/winpython/winpython/releases/download/8.0.20240501/Winpython64-3.12.3.1dotb2.exe
📦 Cliente HuggingFace y UV
python -m pip install hf[download] uv
🐇 Aceleración de GPU (Opcional)
Comando para averiguar la versión de CUDA en nuestra máquina
nvcc -V
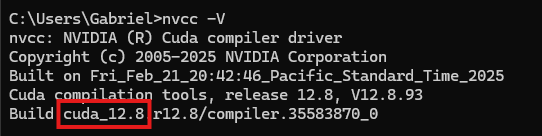
En mi caso, tengo la versión 12.8, así que la ruta del índice de descargas de paquetes debería de terminar en 128
python -m pip install --force-reinstall --no-deps --index-url https://download.pytorch.org/whl/cu128 torch
Instalamos la variante GPU de onnxruntime:
python -m pip install onnxruntime-gpu
💾 Instalación
Importante
En mi caso, UV da un mensaje de error en donde dice que el nombre de la biblioteca no coincide, y adicionalmente, que en windows la copia local no es un enlace simbólico, aunque lo que necesitamos es que, los archivos se copien al lugar especificado, así que se pueden establecer las siguientes variables de entorno para lidiar con éstos detalles, en lo personal uso SETLOCAL para evitar problemas con otras instalaciones.
SET UV_SKIP_WHEEL_FILENAME_CHECK=1 SET UV_LINK_MODE=copy
python -m uv pip install https://github.com/KittenML/KittenTTS/releases/download/0.8/kittentts-0.8.0-py3-none-any.whl
📝 Código de Ejemplo
Nota: KittenTTS descarga el modelo especificado, usando el cliente de HuggingFace.
from kittentts import KittenTTS
m = KittenTTS("KittenML/kitten-tts-mini-0.8")
audio = m.generate("This high quality TTS model works even without a GPU.", voice='Jasper' )
# available_voices : ['Bella', 'Jasper', 'Luna', 'Bruno', 'Rosie', 'Hugo', 'Kiki', 'Leo']
# Save the audio
import soundfile as sf
sf.write('output.wav', audio, 24000)🔖 Más información
- Video de AI Search 🇺🇲: https://youtu.be/fnMAIa2PEAk?t=500&si=G73ygkGDGABy_0d_
- Repositorio en GitHub: https://github.com/KittenML/KittenTTS
- Demo desde el navegador: https://clowerweb.github.io/kitten-tts-web-demo/
- Demo en el espacio de HugginFace: https://huggingface.co/spaces/KittenML/KittenTTS-Demo