Después de un corto tiempo de espera, sale Z-Image (Base), la versión completa de Z-Image Turbo (ZIT), un modelo que combina la calidad de imagen y velocidad.
Importante
La bandera de inicio –fast en el archivo run_(algo).bat de lanzamiento de ComfyUI, provoca que las imágenes generadas terminen completamente en negro.
https://huggingface.co/city96/Qwen-Image-gguf/discussions/1#6892654731c9796ce6124437
Instalación
Descarga de archivos
Archivos necesarios: https://huggingface.co/Comfy-Org/z_image/tree/main/split_files
| Nombre | Tamaño |
|---|---|
| z_image_bf16.safetensors | 12.3GB |
| qwen_3_4b.safetensors | 8.04GB |
| ae.safetensors | 335MB |
Nota: qwen_3_4b.safetensors y ae.safetensors son los mismos de Z-Image Turbo.
Variante GGUF para Tarjetas de 8GB VRAM: https://huggingface.co/unsloth/Z-Image-GGUF/tree/main
| Nombre | Tamaño |
|---|---|
| z-image-Q8_0.gguf | 7.22 GB |
Ubicación de archivos
📂 ComfyUI/
└── 📂 models/
├── 📂 diffusion_models/
│ └── z_image_bf16.safetensors
|
├── 📂 unet/
│ └── z-image-Q8_0.gguf
|
├── 📂 text_encoders/
│ └── qwen_3_4b.safetensors
|
└── 📂 vae/
└── ae.safetensorsParámetros
Samplers (bf16)

Schedulers (bf16)

Steps

bf16 vs q8_0
Generación de prueba
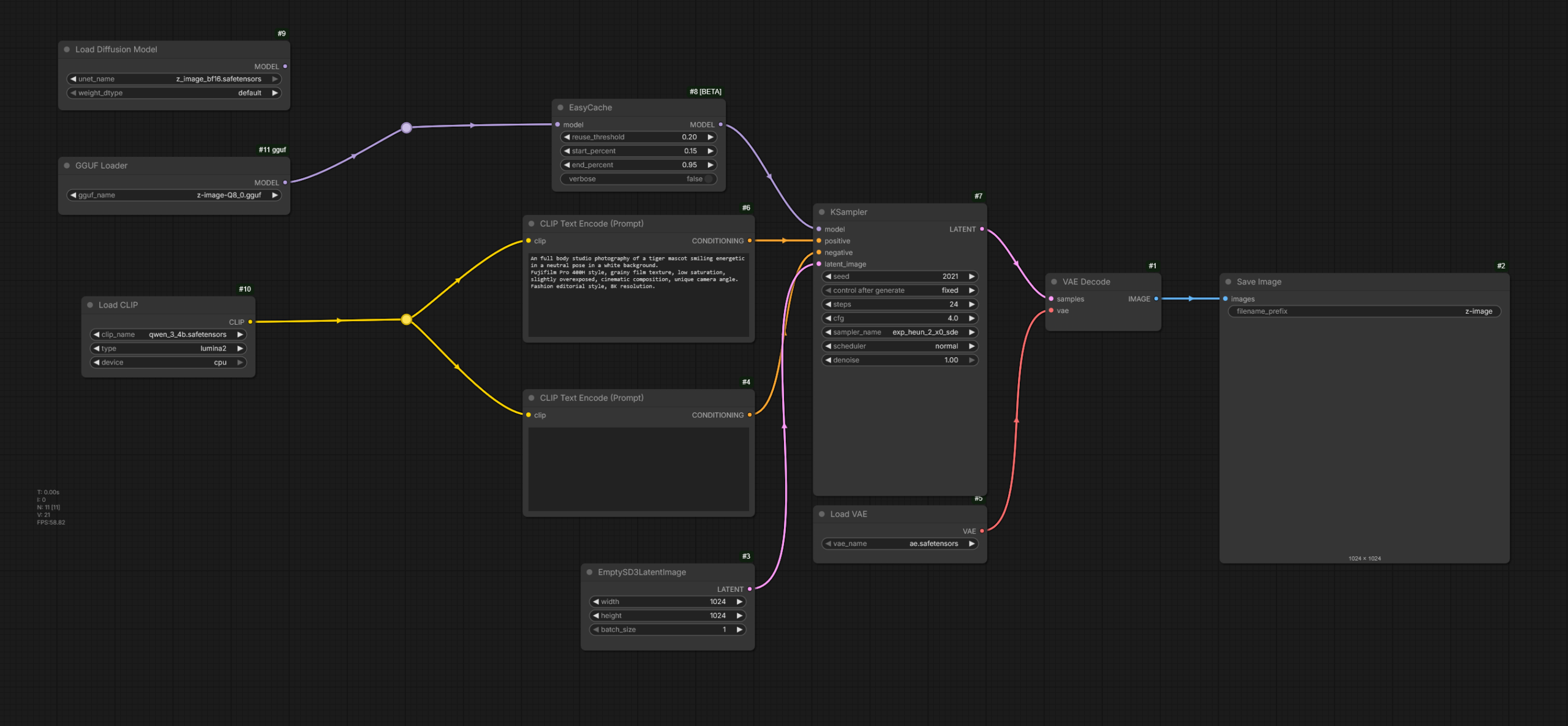

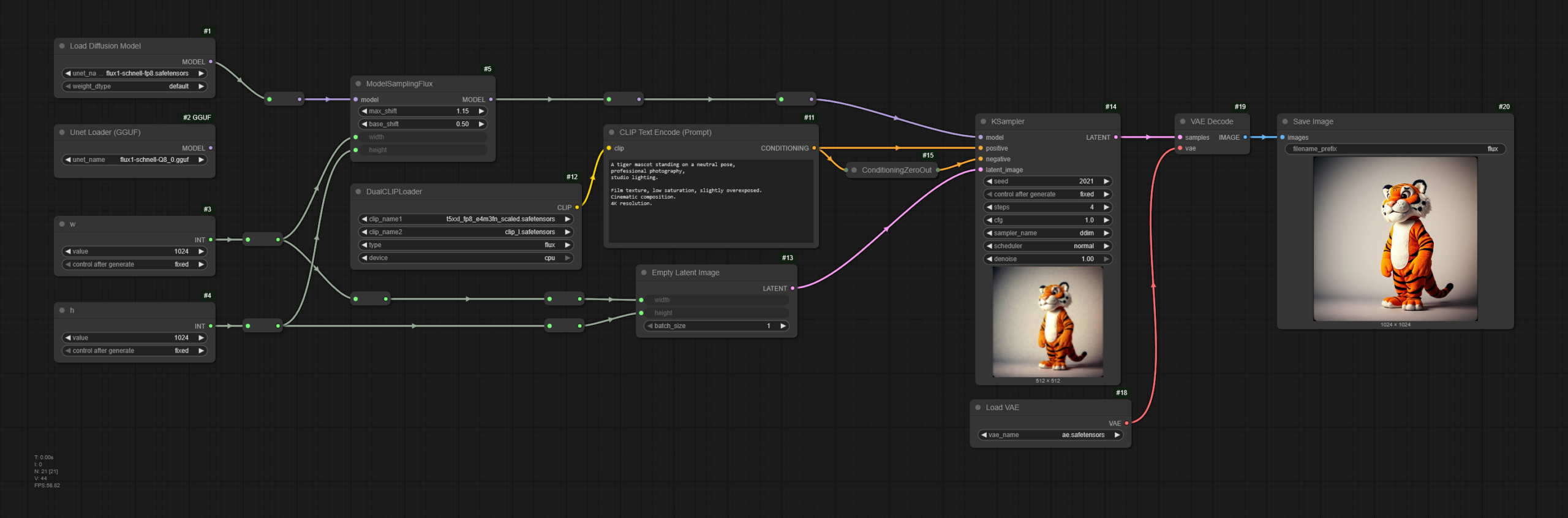
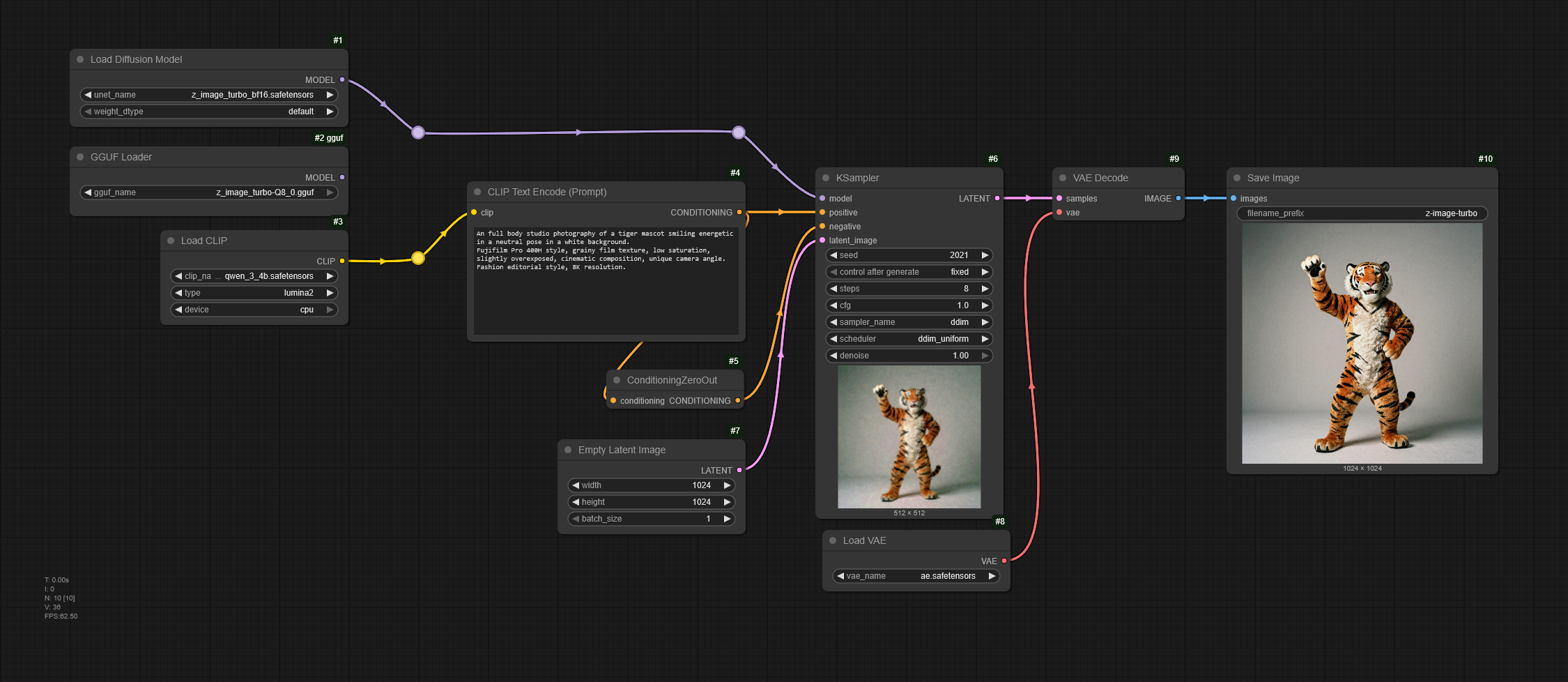
- GGUF Name: z-image-Q8_0.gguf
- Seed: 2011
- Steps: 24
- Width: 1024 (px)
- Height: 1024 (px)
- Sampler: exp_heun_2_x0_sde
- Scheduler: Normal
An full body studio photography of a tiger mascot smiling energetic in a neutral pose in a white background.
Fujifilm Pro 400H style, grainy film texture, low saturation, slightly overexposed, cinematic composition, unique camera angle. Fashion editorial style, 8K resolution.Conclusiones
Una de las principales diferencias con la versión Turbo, es que, a simple vista, se adhiere más al prompt; y ahora tiene la posibilidad de usar un prompt negativo, a costa de un mayor tiempo de generación, cosas que se puede mitigar con el uso de del nodo EasyCache, que nos ayuda a reducir el tiempo de generación a casi la mitad.
La versión FP8 y Q8, son el tope para una tarjeta de 8GB de VRAM, al igual que Z-Image Turbo, aunque en lo personal, prefiero el estilo de Z-Image Turbo.
Fuente
- Z-Image (Comfy.org) – https://docs.comfy.org/tutorials/image/z-image/z-image